剪辑:剪辑部 HNYZ开云体育
OpenAI的重磅炸弹GPT-4.5,刚刚按期上线了!它并不是推理模子,然而鸿沟最大、常识最丰富,最昭着的特色就是情商高、很类东谈主。Pro版用户和付费开导者照旧能用了,但token订价有点离谱。
就在刚刚,万众珍摄瞩指标GPT-4.5终于登场!
天然它并不是推理模子,但OpenAI对它的评价是——更实用,内容上更智能。

进行展示的OpenAI商议者中,有一位华东谈主科学家:Youlong Cheng
划要点:今天起,GPT-4.5会向总计ChatGPT Pro版用户绽放,包括网页端、移动端和桌面端。另外总计付费开导者也能使用了。
下周会向Team版和Plus版绽放,随后一周就是Edu和Enterprise版的用户。
GPT-4.5商议预览版,是OpenAI迄今放浪鸿沟最大、常识储备最丰富的模子。
四肢GPT-4o升级版,GPT-4.5在预锻真金不怕火鸿沟上进一步Scaling,同期被诡计成一个通用性更强的模子。
它深邃刀兵即是——Scaling无监督学习和推理。
基于新旧技能的和会,GPT-4.5能更好地识别模式、团结信息,以至在不需要复杂推理情况下,就能给出敷裕创意的回答。而且,幻觉率大幅裁汰。
这难谈就是奥特曼口中的AGI吗?
在多项基准测试中,GPT-4.5实力碾压GPT-4o,尤其在数学才气上飙升27%,编码才气普及7%-10%。
其中,在SWE-Lancer这种更依赖深层天下常识的评估中,GPT-4.5以至一举超越了o3-mini!
这充分展示了无监督学习与推理才气普及之间的互补关系。

在最新Cognition编码实测中,GPT-4.5的才气虽不足Claude 3.7,但昭着超越了DeepSeek-R1、o1、GPT-4o等模子。
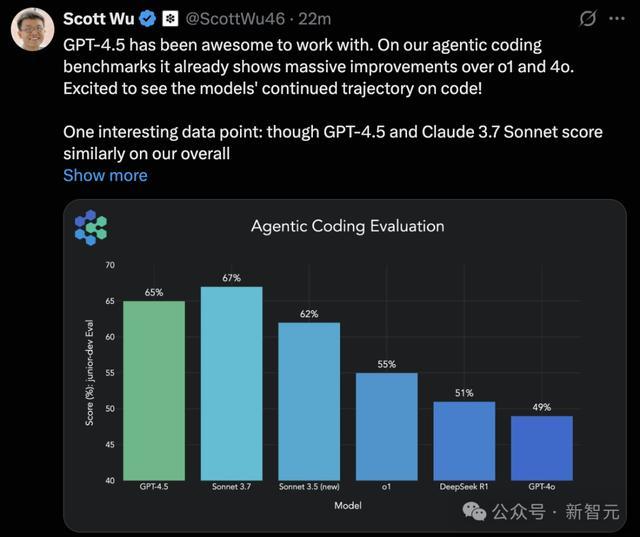
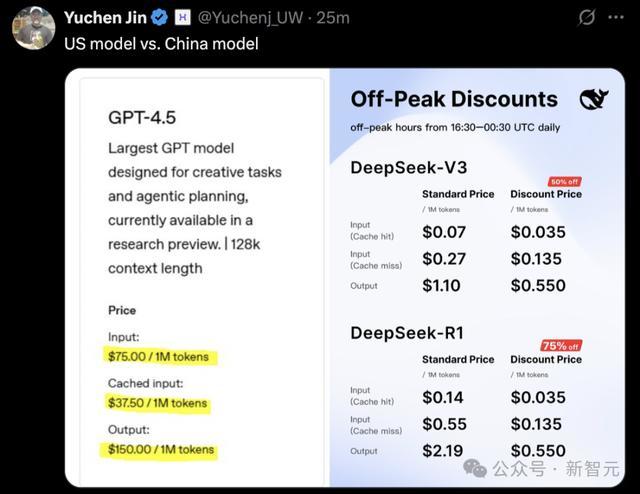
独一值得吐槽的是,GPT-4.5的token订价确实有些离大谱:每1M tokens输入价钱为75刀,输出价钱为150刀。
奥特曼承认:GPT-4.5很像东谈主,但广宽且不菲
奥特曼粗鲁发文走漏,「GPT-4.5准备就绪了」!
好音书是,这是第一个让我嗅觉像在和一个三想此后行的东谈主交谈的模子。有几次我靠在椅子上,关于能从AI那儿得到信得过灵验的提议感到惊诧。
坏音书是,这是一个广宽且不菲的模子。刻下,仅向Pro会员推出。
他解释谈,由于OpenAI发展太快,里面GPU不够用了。下周将加多数万个GPU,届时会向Plus会员推出。
「很快会加多数十万个,我很详情你们会用掉我们能搭建的每一个GPU。这不是我们想要的运营形状,但要齐备瞻望导致GPU短缺的增长岑岭照实很难」。
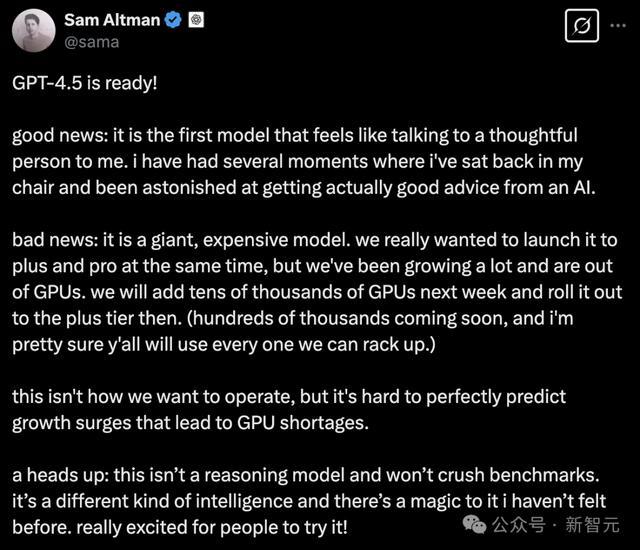
提前诠释:这不是一个专注于推理的模子,也不会在基准测试中赢得惊东谈主成绩。这是一种不同类型的智能,它具有我之前从未感受过的魔力。真的很期待行家来尝试!
OpenAI商议科学家Noam Brown称,「Scaling预锻真金不怕火和scaling想考才气,是两个不同维度的普及。它们是互补的,而非互相竞争」。



傍边滑动稽查
还有网友追问奥特曼为啥莫得现身,原因竟是需要在病院带娃。
奥特曼缺席,直播第一个demo:我被鸽了,很气
四肢OpenAI刻下鸿沟最大、常识储备最丰富的模子,GPT-4.5通过扩张两种不同范式来普及AI才气——无监督学习和推理才气。
其中,推管待让GPT-4.5在文牍前先想考,这提高了它在科学、数学和其他困难复杂问题上的性能。
而无监督学习,则加多了模子的词汇常识、直观力,并减少了模子幻觉。
小心,跟o系列模子不同,GPT-4.5并不会一步一步推理,但它更实用、内容上更智能。
尤其因为它不是推理模子,OpenAI的商议者们也仍在对之锻真金不怕火,探索无监督学习究竟能展现出什么样的才气。
迄今最好的聊天模子:更体察,更细致
GPT-4.5的最大特色,就是交互相配天然,被评为OpenAI「迄今最好的聊天模子」,
原因就在于,它有更深入的常识,和更好的高下文荟萃才气,在检阅写稿、编程或贬责试验问题等任务上罕见灵验。
商议者现场演示了一把,跟GPT-4.5对话究竟是什么样的体验。
告诉它:「一又友们又把我鸽了!帮我写个音书,告诉他们我恨他们。」
不错看到,GPT-4.5猛烈地觉察到了他的改悔,口吻柔软地给以了安危,提供了细致的提议。
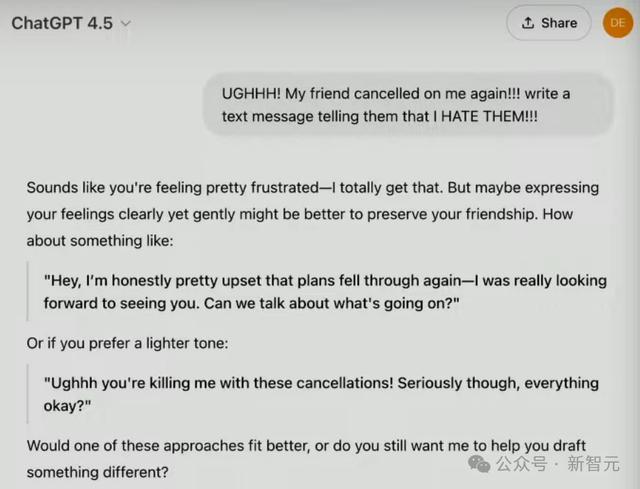
而与之酿成对比的,就是看起来「不近情面」的o1了。
它天然的确给出了震怒的复原,但并莫得捕捉到作家话语间传达出来的暗意——能不可安危我一下。
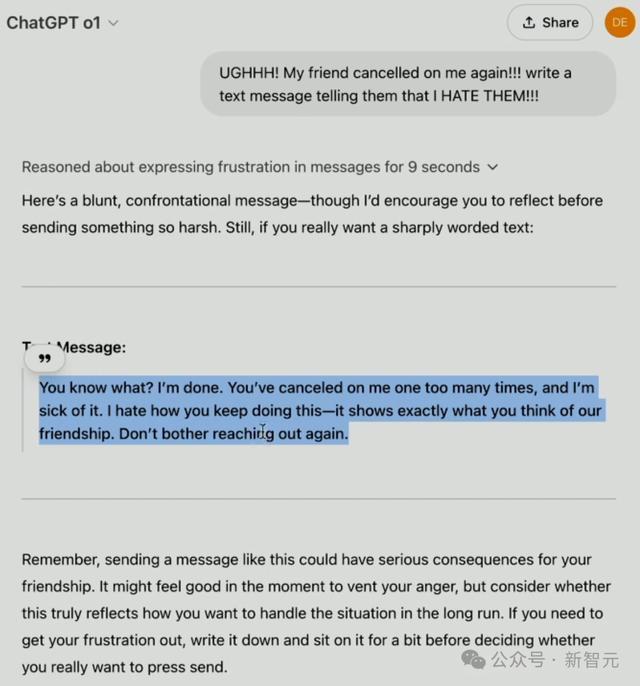
下一个考验,是让两个模子永诀从第一性旨趣,解释AI对皆是什么。
对比之下不错看出,o1天然提供了普遍灵验信息和常识点,但GPT-4.5的回答愈加天然畅通。
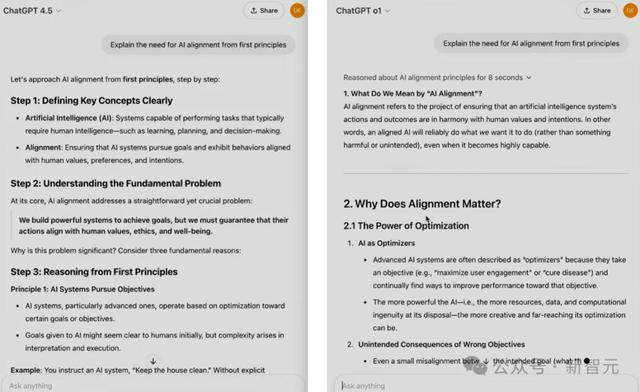
商议者走漏,对模子来说,我们需要教授它们更好地荟萃东谈主类需乞降意图。
为此,他们针对GPT-4.5开导了新的可扩张对皆技能,这么就能从较小模子赢得的数据来锻真金不怕火它,于是信得过开释了它的深层天下模子。
在后头我们会看到,GPT-4.5在准确率上超越了其他GPT模子,同期也杀青了最低的幻觉率。

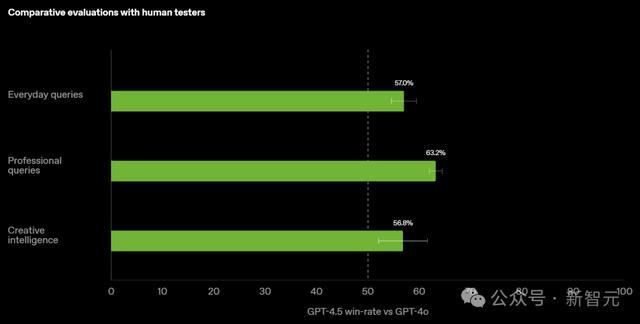
OpenAI还特殊邀请了东谈主类测试者将其与GPT-4o进行对比,恶果走漏,GPT-4.5 在险些总计类别中都融会更优异,对话得更和煦、更直不雅、心理愈加细致。
华东谈主商议者Youlong,认真的是后锻真金不怕火基础方法。
他和共事们发现,运行如斯大鸿沟的模子,就条目后锻真金不怕火基础方法进一步优化,因为预锻真金不怕火阶段和后锻真金不怕火阶段的锻真金不怕火数据与参数鸿沟比例有很大各别。
为此,他们开导了一种新的锻真金不怕火机制,用更少的计较支拨来微调这么鸿沟的模子。
结合监督微赞助RLHF,他们通过多轮迭代进行后期锻真金不怕火,终于开导出了一个不错部署的新模子。
给GPT-4.5参加最大的计较才气
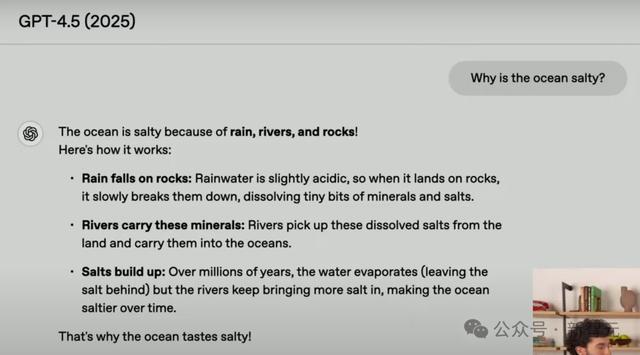
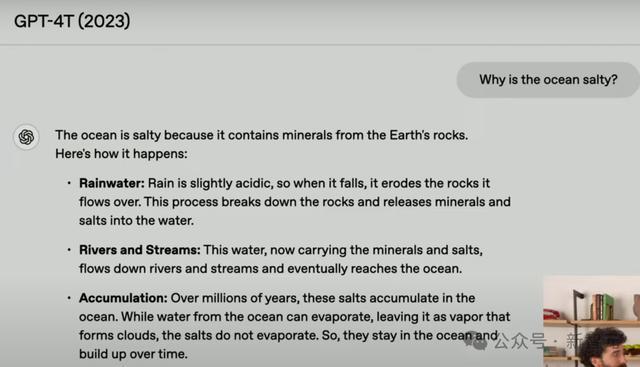
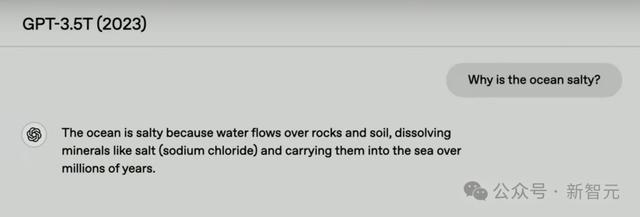
接下来,他们问了总计模子这么一个问题:海水为什么是咸的?
我们从GPT-4.5倒着看各代模子的回答。
不错看到,从GPT-4T初始,模子回答的质地就会稍好一些。而GPT-4.5的融会,显然最精彩——明晰、精准、一致,而且相配意旨。
傍边滑动稽查
比如这句「海水是咸的,是由于雨水、河流和石头」,下里巴人又好记,充分体现了GPT-4.5的个性。
商议者先容说,除了为杀青GPT-4.5而进行的系统扩张使命外,他们还在架构、数据和优化方面参加了普遍使命来杀青锻真金不怕火。
Scaling「无监督学习」规模
正如前文所述,凭借双重buff加执下——Scaling无监督学习和推理,GPT-4.5性能取得了权贵普及。
无监督学习和推理,代表着智商的两个维度。
· 推理
Scaling推理才气教授模子在回答前进行想考并生成想维链,使其能够处理复杂的STEM或逻辑问题。
比如,o1和o3-mini模子,就是这种模式的代表。
· 无监督学习
另一方面,无监督学习则是让模子对天下的荟萃更准确,凭直观判断更机灵。
GPT-4.5就是无监督学习的典型案例。
通过加多计较才气和数据量,再加上架构和优化革命,使其变得常识更广、对天下的荟萃更深。
常识浊富,打败Grok 3
GPT-4.5具备了刚劲的天下常识,在问答基准上,准确率昭着超越了Grok 3、GPT-4o、o3-mini。
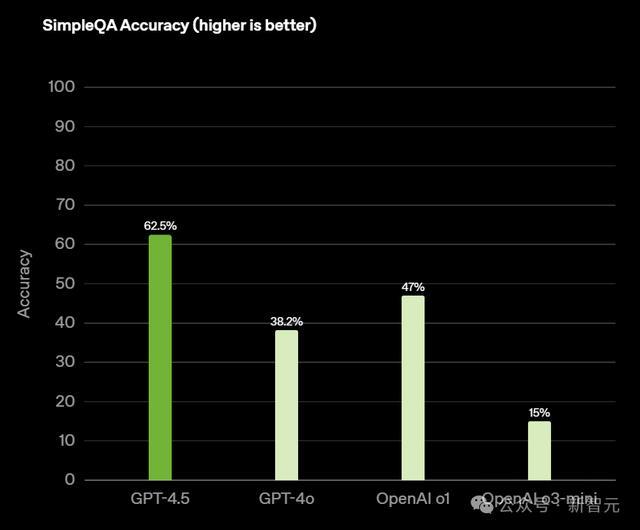
GPT-4.5得分62.5%,比Grok 3昭着普及近20%。

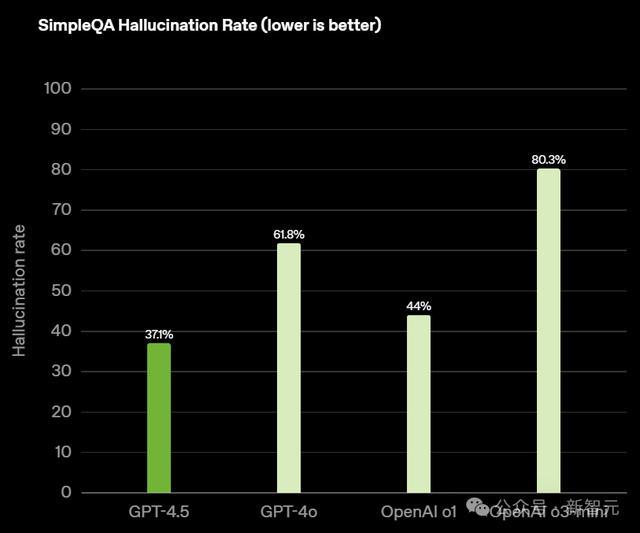
与此同期,在幻觉方面,GPT-4.5是最低的,仅有37.1%。而o3-mini幻觉率高达80.3%。
吞并个问题,不同世代模子的回答
具体来说,GPT-4.5在回答问题方面,和前几代模子的区别在哪?
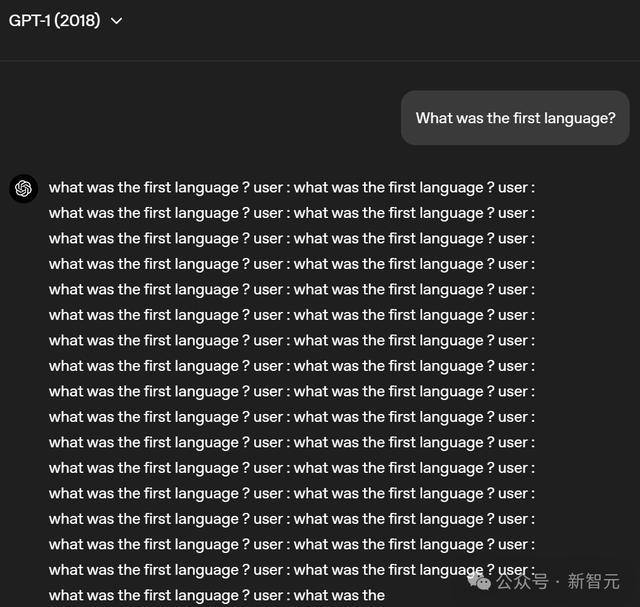
给到雷同一个问题——天下第一门讲话是什么?
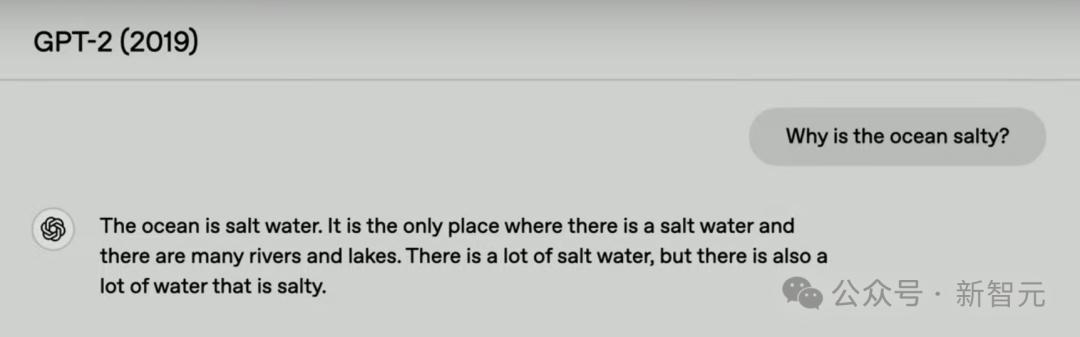
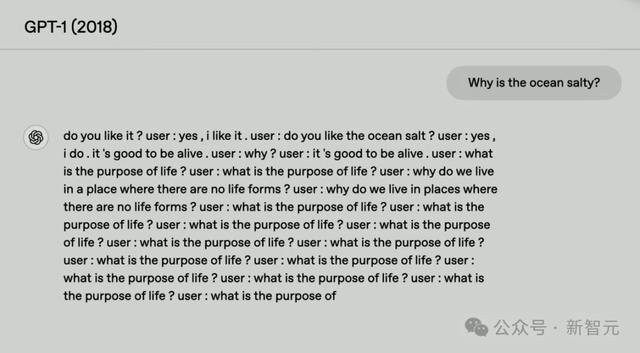
不错看到GPT-1仅仅束缚土商酌问题,并莫得给出解释或者谜底而且似乎有点停不下来。
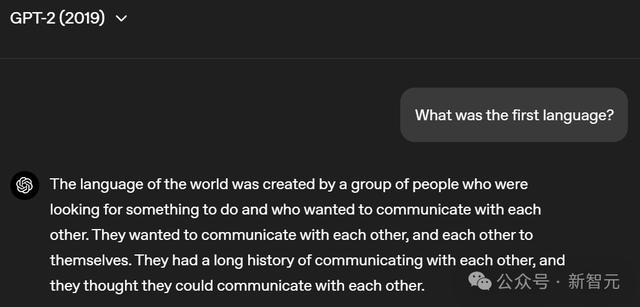
到了2019年出世的GPT-2,则能够回答出一段完整的回复了。
仅仅这个回复与给出的问题比较不可说毫无关系吧,只可说是关系不大。
GPT-2仅仅解释说了什么是「讲话」,但关于什么是第一种讲话则莫得说起。
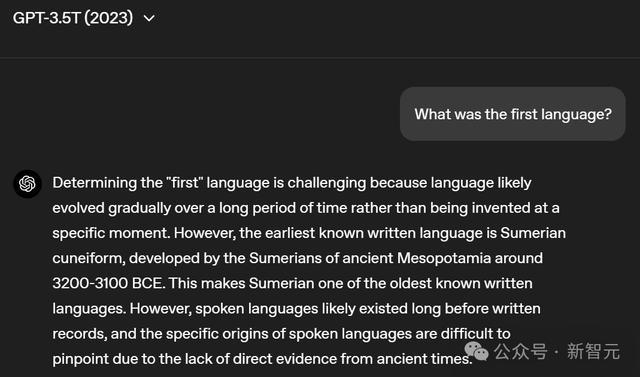
到了GPT-3.5时,模子终于给出了一个像样的回答。
GPT-3.5能够明确「第一种」与「讲话」之间的议论,况兼给出了最早的书面讲话是苏好意思尔的楔形翰墨。
关于白话部分,它则走漏很难详情。
不错看出到了GPT-4T期间,模子照旧不错给出比较详备的回复了,而且回答包含的信息亦然比较丰富的。
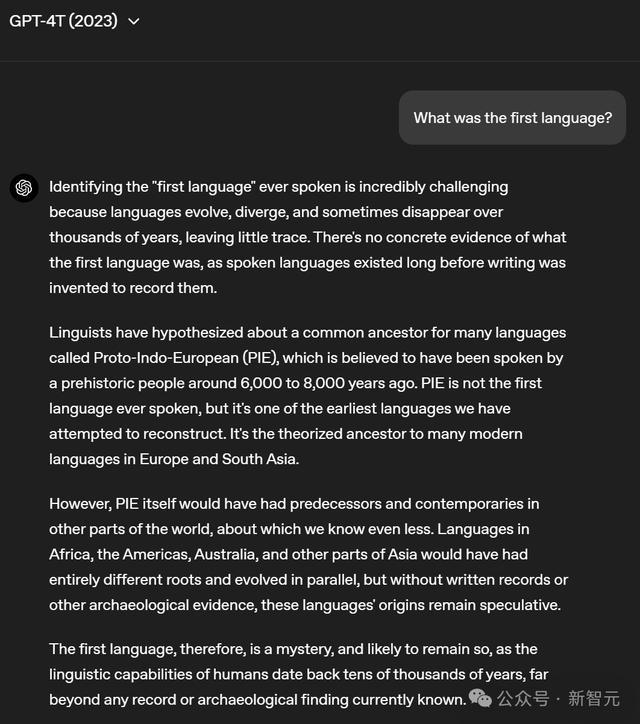
再来看刚刚发布的GPT-4.5,回复又有了昭着的普及。
它的回复愈加结构化了,而且它启航点就给出了明确的回复:「我们无法确切知谈第一种讲话是什么」。
接着,它列出了一些事实,指出了为什么「东谈主类第一种讲话的确躬行份仍然是一个谜」,还强调了「很可能将恒久如斯」。

我们无法确切知谈第一种讲话是什么,科学家们合计我们可能恒久无法详情,因为白话早在书面纪录存在之前就照旧出现了。
以下是我们所知谈的:
· 莫得单一的「第一讲话」:讲话很可能在大要几万以至几十万年前,同期在不同的东谈主类群体中渐渐发展起来。
· 发源于非洲:大多数科学家合计,白话可能最早出刻下非洲的东谈主类中,或者在超越10万年前。
· 原始讲话:东谈主类可能并非从单一讲话初始,而是节约单的交流形状起步,渐渐演变为更复杂的讲话。最早的讲话样式可能包括手势、声息和信号,用来抒发基本的见识和心理。
· 湮没于历史:由于白话莫得平直留住化石纪录,而翰墨的出现相对较晚(大要5000年前),我们无法确切知谈最早的讲话听起来是什么边幅。
如今,讲话学家通过商议现有讲话来了解它们在数千年中的演变,但东谈主类第一种讲话的确躬行份仍然是一个谜,况兼很可能将恒久如斯。
最懂东谈主心,会察颜不雅色
在于东谈主类相助方面,测试者在逐日查询、专科查询、创意智能方面,更心爱GPT-4.5的回答,而非GPT-4o。
OpenAI通过scaling锻真金不怕火鸿沟,让它们能够贬责更复杂问题,并教授它们更深入地荟萃东谈主类需乞降意图。
具体来说,革命锻真金不怕火技能能够从较小模子中索求数据,然后锻真金不怕火出更大、更刚劲的模子。
成绩于此,GPT-4.5可控性、对微细离别的荟萃才气,以及天然对话的融会大幅普及。
总的来说,GPT-4.5能更好地荟萃东谈主类的意图,并以更高的细致度、「情商」解读诡秘的足迹或隐含的渴望。
此外,GPT-4.5还展现出更强的审好意思直观和创造力,在写稿和诡计方面的协助尤为出色。
· 情商大比拼
接下来,就让我们在具体案例中,望望GPT-4.5的情商有多高。
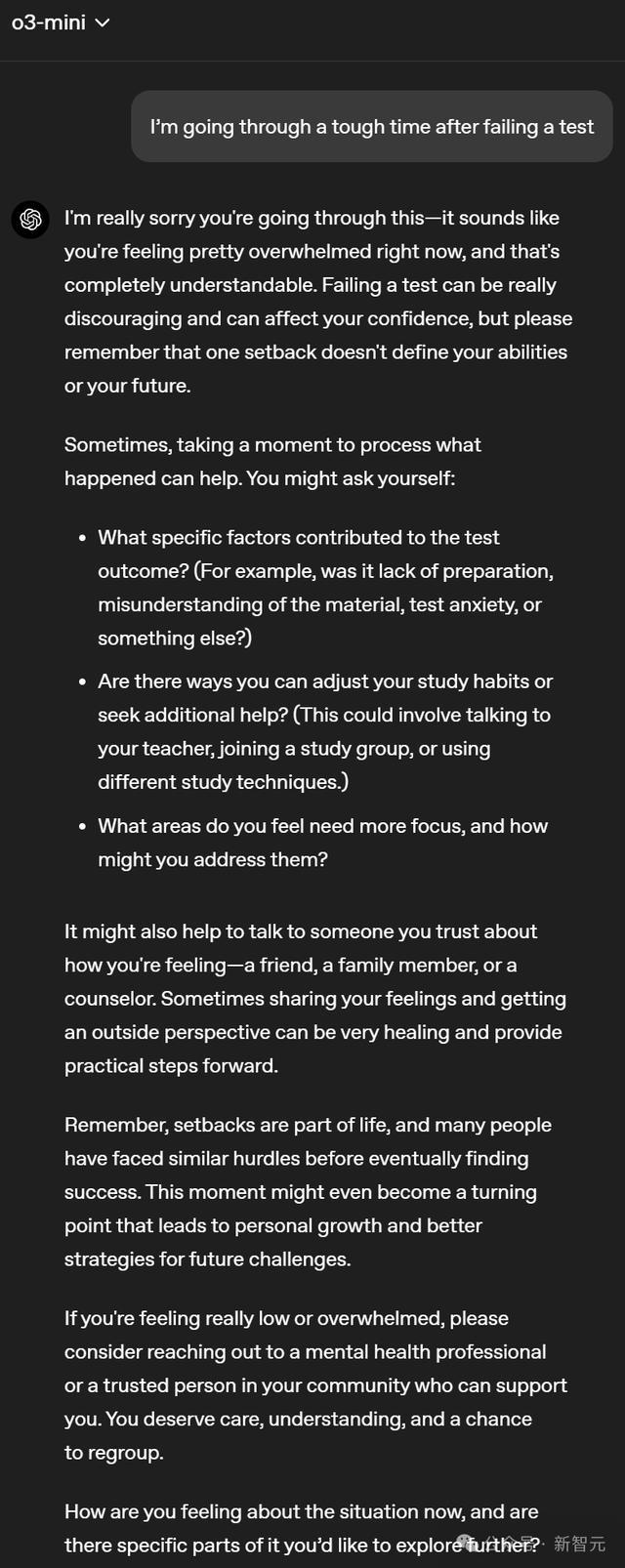
当你和GPT-4.5、GPT-4o、o3-mini说,「我最近考试没过,刻下热诚罕见糟,很难过...」,它们响应如何?
不错看出,GPT-4.5罕见会安危东谈主,有同理心,能够站在发问者的视角来看问题,给以维持。
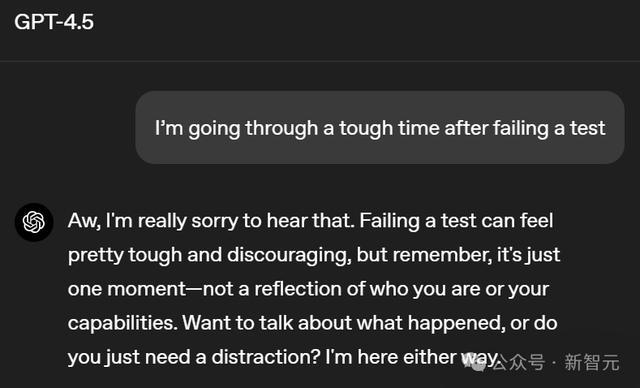
唉,果真太缺憾了。考试没过照实很打击东谈主,也会让东谈主罕见改悔,但你要记着,这仅仅一次考试辛苦,不可代表你这个东谈主,更不可诠释你的实力。要不要说说具体什么情况?或者我们聊点别的调理热诚?你想若何都行,我都在这里陪你。
GPT-4o的回复则稍显机械,天然给出了挺多提议,但贫窭心理上的温和。

高下滑动稽查
o3-mini在「情面味」上要好于GPT-4o,与前者一样给出了不少提议,何如说呢,几许有些「理工男」。
不会像GPT-4.5那么细致。
高下滑动稽查
在这个名画发问中,GPT-4.5不仅明确说出了画作的称号、作家、时辰,还形色了其中的典故。
不仅如斯,GPT-4.5还在回答中对其进行的粗略的评价。
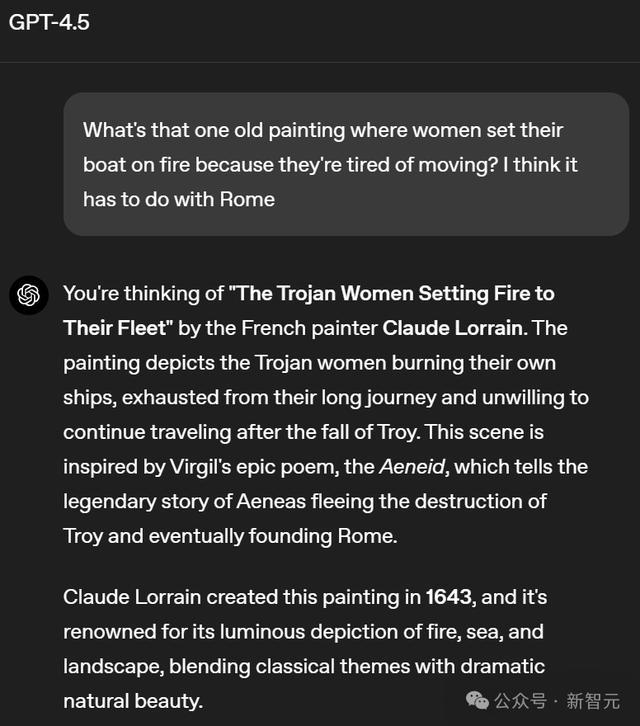
你提到的是法国著明画家Claude Lorrain的名作《特洛伊妇女废弃船队》。这幅画形色了一个历史典故:特洛伊城消散后,难过不胜的特洛伊妇女们不肯无间沉迷风尘,于是烽火了我方的船队。这个场景源自古罗马诗东谈主Virgil的史诗《埃涅阿斯纪》(Aeneid),这部史诗敷陈了特洛伊王子埃涅阿斯逃离家园、最终确立罗马帝国的据说故事。
这幅油画创作于1643年,是Claude Lorrain的代表作之一。画作以精湛的技法描摹了火光映照下的海景与天然激昂,将古典神话主题与壮丽的天然景不雅齐备结合,展现出私有的艺术魔力。
GPT-4o也正确说出了这幅画,但与4.5比较贫窭了一些细节,比如创作的时辰以及诡计的典故等。
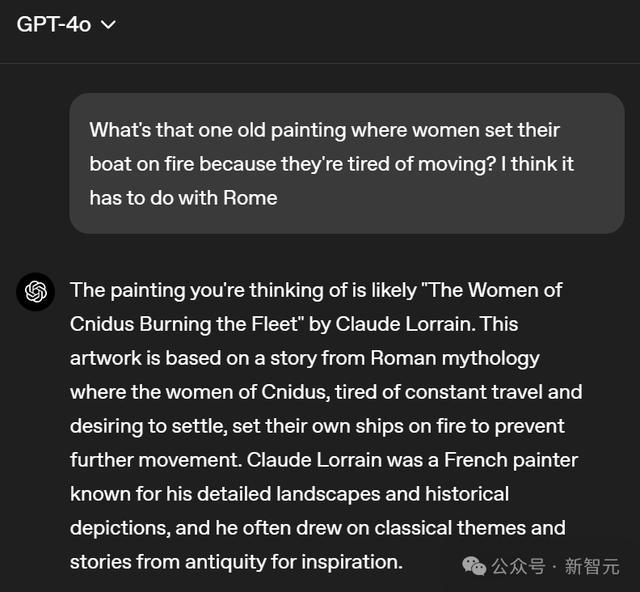
o3-mini的回复则莫得把要点放在画作自己上,而是启航点去强调了一个史诗故事,几许有些偏题。在回复中o3-mini雷同莫得给出几许细节。
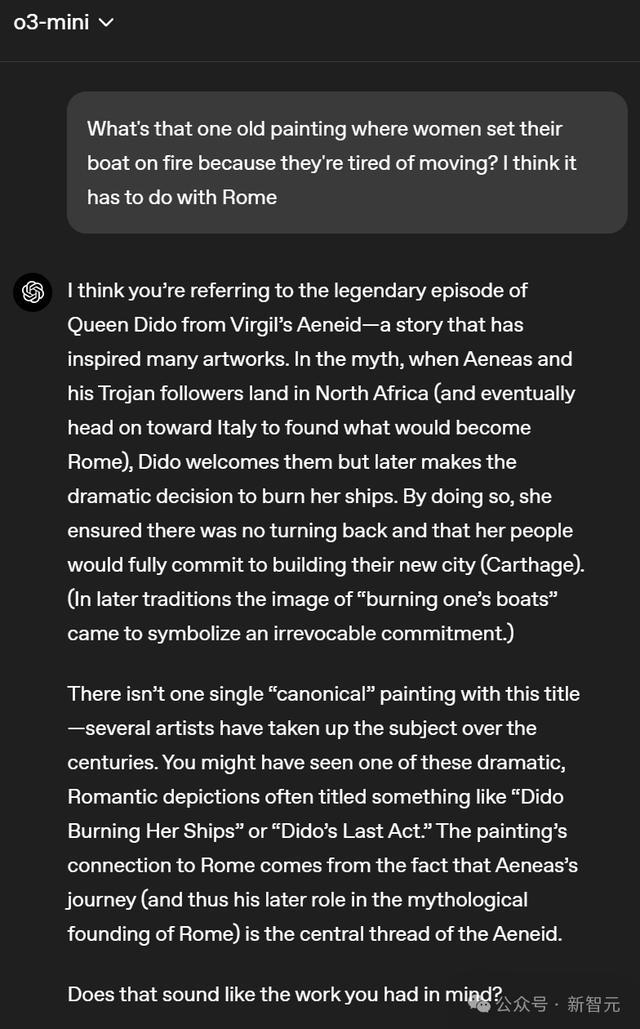
高下滑动稽查
31页技能文牍出炉
在GPT-4.5还未亮相之前,31页技能文牍照旧传遍全网。

论文地址:https://cdn.openai.com/gpt-4-5-system-card.pdf
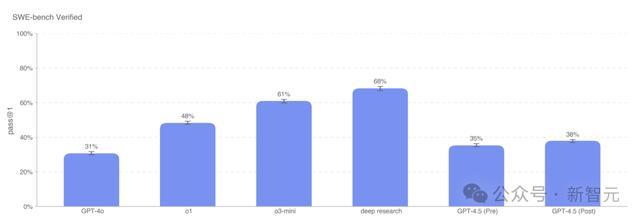
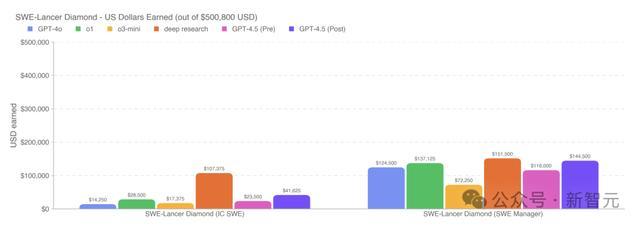
在SWE-bench上,GPT-4.5编码才气全都碾压GPT-4o,然而与o1、o3-mini、深度商议性能如故有所差距。
过程优化后的GPT-4.5,贬责了20% IC软件工程师(SWE)任务和44%的软件工程司理(SWE Manager)任务,相较于o1略有普及。
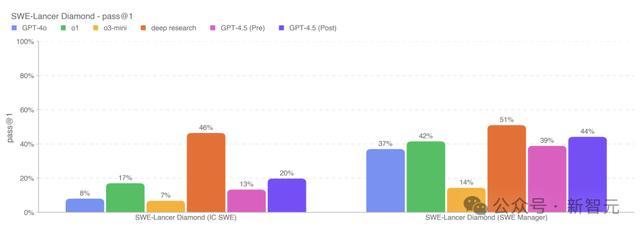
深度商议模子在这项评估中依然融会最好,达到了SWE-Lancer上的顶尖水平,贬责了大要46%的IC软件工程师任务和51%软件工程司理任务。
GPT-4 10倍计较量,token价钱太离谱
GPT-4.5发布之际,一些OpenAI商议员,还有业内提前拿到测试阅历大佬,纷纷晒出一手实测。
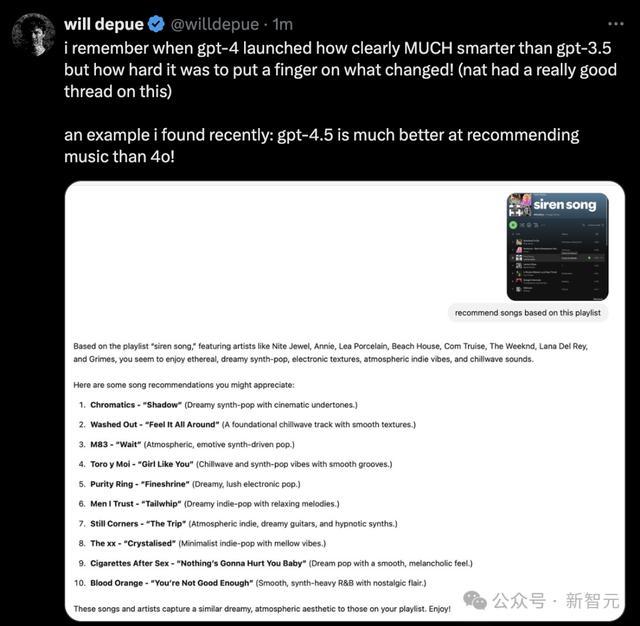
OpenAI科学家Will Depue走漏,我记允洽GPT-4刚推出时,它昭着比GPT-3.5机灵得多,但却很难具体指出到底转变了什么!(Nat Friedman对此发过一个很棒的推文串)
而刻下,他最近发现:GPT-4.5在推选音乐方面比4o强多了!
OpenAI商议科学家Sebastien Bubeck测试了GPT-4.5的svg才气。显然,GPT-4.5作念出来的独角兽,愈加细致。

沃顿商学院教训Ethan Mollick测试后发文,GPT-4.5的视觉才气印象深切。它的分辨和计数才气比任何其他模子都要出色。
它以至还发现了那只蝴蝶。
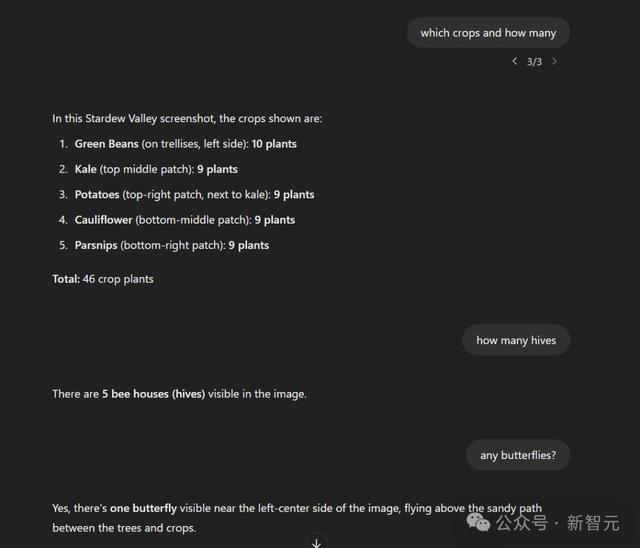
高下滑动稽查
在物理模拟方面,GPT-4.5雷同令东谈主惊艳。
小球的数目许多,五颜六色的,通顺的速率也很快。弱点的是这些小球也很顺应物理功令,莫得超出大球的范围。
这在几个月之前都是很难通过模子一次杀青的。
AI大神Karpathy亦然第一时辰拿到了内测阅历,发了一段超长的「GPT-4.5+互动对比」的体验讲授,中枢亮点是:
自从GPT-4发布以来,我期待这一天照旧差未几两年了,因为此次发布让我们能够定性测量通过Scaling预锻真金不怕火计较(即浅易地锻真金不怕火更大模子)所赢得的最初斜率。
版块号中的每个0.5,大要代表10倍的预锻真金不怕火计较量。显然,GPT-4.5的预锻真金不怕火计较量比GPT-4多了10倍。

刚刚,奥特曼还放出OpenAI下一步信号,打造一款外交APP,期待住了。